
Advanced Database Connection Pooling Configuration¶
- Database connections are valuable resources and as such shall be managed with care:
- they are heavy to create and maintain for the database server itself since they are usually child processes of the DBMS server process
- being processes that means that creating a connection is not a zero-cost process therefore we should avoid creating connections as we need to connect to a DB but we should tend to create them in advance in order to minimize the impact of the time needed to create them on the time needed to serve a request.
- as a consequence of the fact that a connection require non negligible resources on the server DBMS DBAs tend to
- limit the number of connections globally available (e.g. PostgreSQL by default has a limit set to 100)
- limit the lifetime of connections created in order to discourage clients from retaining connections for a really long time
The purpose served by a connection pool is to maintain connections to an underlying database between requests. The benefit is that connection set-up only need to occur once on the first request while subsequent requests use existing connections and achieve a performance benefit as a result.
Ok, now let’s go into GeoServer specifics. In most GeoServer DataStores you have the possibility to use the JNDI [1] or the standard store which basically means you can have GeoServer manage the connection pool for you or you can configure it externally (from within the Application Server of choice) and then have GeoServer lean onto it to get connections. Baseline is, one way or the other you’ll always end-up using a connection pool in GeoServer.
GeoServer Internal Connection Pool Parameters¶
Whenever a data store backed by a database is added to GeoServer, an internal connection pool for which relies on Apache Commons DBCP [2] is created by default. This connection pool is configurable, however let me say this upfront, the number of pool configuration parameters that we expose is a subset of the possible ones, although the most interesting are there. Namely there are a few that you might want to customize. Here below you can find some more details on the available connection parameters.
max connections The maximum number of connections the pool can hold. When the maximum number of connections is exceeded, additional requests that require a database connection will be halted until a connection from the pool becomes available and eventually times out if that’s not possible within the time specified in the connection time-out. The maximum number of connections limits the number of concurrent requests that can be made against the database. min connections
- The minimum number of connections the pool will hold. This number of connections is held even when there are no active requests. When this number of connections is exceeded due to serving incoming requests additional connections are opened until the pool reaches its maximum size (described above). The implications of this number are multiple:
-1- If it is very far from the max connections this might limit the ability of the GeoServer to respond quickly to unexpected or random heavy load situations due to the fact that it takes a non negligible time to create a new connections. However, this set up is very good when the DBMS is quite loaded since it tends to use as less connections as possible at all times.
-2- If it is very close to the max connections value the GeoServer will be very fast to respond to random load situation. However, in this case the GeoServer would put a big burden on DBMS shoulders as the the poll will try to hold all needed connections at all times.
validate connections Flag indicating whether connections from the pool should be validated before they are used. A connection in the pool can become invalid for a number of reasons including network breakdown, database server timeout, etc.. The benefit of setting this flag is that an invalid connection will never be used which can prevent client errors. The downside of setting the flag is that a small performance penalty is paid in order to validate connections when the connection is borrowed from the pool since the validation is done by sending small query to the server. However, the cost of this query is usually small, as an instance on PostGis the validation query is Select 1. fetch size The number of records read from the database in each network exchange. If set too low (<50) network latency will affect negatively performance, if set too high it might consume a significant portion of GeoServer memory and push it towards an Out Of Memory Error. Defaults to 1000, it might be beneficial to push it to a higher number if the typical database query reads much more data than this, and there is enough heap memory to hold the results. connection timeout Time, in seconds, the connection pool will wait before giving up its attempt to get a new connection from the database. Defaults to 20 seconds. This timeout kicks in during heavy load conditions when the number of requests needing a connection to a certain DB outnumber greatly the number of available connections in the pool, therefore some requests might get error messages due to the timeouts while acquiring a connection. This condition is not per se problematic since usually a request does not use a DB connection for its entire lifecycle hence we do not need 100 connections at hand to respond to 100 requests; however we should strive to limit this condition since it would queue threads on the connection pool after they might have allocated memory (e.g. for rendering). We will get back to this later on. max open prepared statements Maximum number of prepared statements kept open and cached for each connection in the pool. max wait Number of seconds the connection pool will wait before timing out attempting to get a new connection (default, 20 seconds). validate connection It forces GeoServer to check that the connections borrowed from the pool are valid (i.e. not closed on the DMBS side) before using them. Test while idle Periodically test if the connections are still valid also while idle in the pool. Sometimes performing a test query using an idle connection can make the datastore unavailable for a while. Often the cause of this troublesome behaviour is related to a network firewall placed between Geoserver and the Database that force the closing of the underlying idle TCP connections. Evictor run periodicity Number of seconds between idle object evictor runs. Max connection idle time Number of seconds a connection needs to stay idle before the evictor starts to consider closing it. Evictor tests per run Number of connections checked by the idle connection evictor for each of its runs.
Prepared statements consideration¶
Prepared statements are used by databases to avoid re-planning the data access every time, the plan is done only once up-front, and as long as the statement is cached, the plan does not need to be re-computed.
In business applications fetching a small amount of data at a time this is beneficial for performance. However, in spatial ones where we typically fetch thousands of rows, the benefit is limited and sometimes turns into a performance problem. This is the case with PostGIS, that is able to tune the access plan by inspecting the requested BBOX and deciding if a sequential scan is preferable (the BBOX really accesses most of the data) or using the spatial index is best instead. So, as a rule of thumb, when working with PostGIS, it’s better not to enable prepared statements.
With other databases there are no choices, Oracle currently works only with prepared statements, SQL server only without them (this is often related to implementation limitations than database specific issues).
There is an upside of using prepared statement though: no sql injection attacks are possible when using them. GeoServer code tries hard to avoid this kind of attack when working without prepared statements, but enabling them makes the attack via filter parameters basically impossible.
Final Thoughts¶
Summarising, when creating standard DataStores for serving vector data from DBMS in GeoServer you need to remember that internally a connection pool will be created. This approach is the simplest to implement but might lead to an inefficient distribution of the connections between different stores in the following cases:
- if we tend to separate tables into different schemas this will lead to the need for creating multiple stores to serve them out since GeoServer works best if the “schema” parameter is specified, this leading to the creation of (mostly unnecessary) connection pools
- if we want to create stores in different workspaces connecting to the same database this again will lead to unnecessary duplication of connection pools in different store leading to inefficient usage of connections
Long story short, the fact that the pool is internal with respect to the stores may lead to inefficient usage of connections to the underlying DBMS since they will be splitted between multiple stores limiting the scalability of each of them: in fact having 100 connections shared between N normal DataStore will impose limits to the maximum number that each can use, otherwise if we managed to keep the connections into a single pool shared, in turn, with the various DataStore we would achieve a much more efficient sharing between the store as, as an instance, a single store under high load could scale to use all the connections available.
Configuration of a JNDI connection pool with Tomcat¶
Many DataStore in GeoServer provide the option of exploiting Java Naming and Directory Interface or JNDI for managing the connections pools. JNDI allows for components in a Java system to look up other objects and data by a predefined name. A common use of JNDI is to set-up a connection pool in order to improve the database resource management.
In order to set-up a connection pool, Tomcat needs to be provided with a JDBC driver for the database used and the necessary pool configurations. Usually the JDBC driver can be found in the website of the DBMS provider or can be available in the database installation directory. This is important to know since we are not usually allowed to redistribute them.
The JDBC driver for creating connection pool to be shared via JNDI shall be placed in the $TOMCAT_HOME/lib directory, where $TOMCAT_HOME is the directory on which Tomcat is installed.
Note
Make sure to remove the JDBC driver from the Geoserver WEB-INF/lib folder when copied to the Tomcat shared libs to avoid issues in JNDI DataStores usage.
The configuration is very similar between different databases. Here below some typical examples will be described.
PostgreSQL JNDI Configuration¶
For configuring a PostgreSQL JNDI pool you have to remove the Postgres JDBC driver (it should be named postgresql-X.X-XXX.jdbc3.jar) from the GeoServer WEB-INF/lib folder and put it into the TOMCAT_HOME/lib folder.
Tomcat Set-up¶
The first step to perform for creating a JNDI DataSource (connection pool) is to edit the context.xml file inside $TOMCAT_HOME/conf directory (or %TRAINING_ROOT%/tomcat/instances/instance1/conf in the case of Windows, for this workshop). This file contains the different JNDI resources configured for Tomcat.
In this case, we are going to configure a JNDI DataSource for a PostgreSQL database. If the file is not present you should create it and add a content similar to the following:
<Context>
<Resource
name="jdbc/postgres" auth="Container" type="javax.sql.DataSource"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/testdb"
username="admin"
password="admin"
maxActive="20"
maxIdle="10"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
validationQuery="SELECT 1"/>
</Context>
Note
If the file is already present, do not add the <Context></Context> labels.
In the previous XML snippet we configured a connection to a PostrgreSQL database called testdb which have the hostname as localhost and port number equal to 5432.
Note
Note that the user shall set proper username and password for the database.
Some of the parameters that can be configured for the JNDI connection pool are as follows:
- maxActive : The number of maximum active connections to use.
- maxIdle : The number of maximum unused connections.
- maxWait : The maximum number of milliseconds that the pool will wait.
- poolPreparedStatements : Enable the prepared statement pooling (very important for good performance).
- maxOpenPreparedStatements : The maximum number of prepared statements in pool.
- validationQuery : (default null) A validation query that double checks the connection is still alive before actually using it.
- timeBetweenEvictionRunsMillis : (default -1) The number of milliseconds to sleep between runs of the idle object evictor thread. When non-positive, no idle object evictor thread will be run.
- numTestsPerEvictionRun : (default 3) The number of objects to examine during each run of the idle object evictor thread (if any).
- minEvictableIdleTimeMillis : : (default 1000 * 60 * 30) The minimum amount of time, in milliseconds, an object may sit idle in the pool before it is eligable for eviction by the idle object evictor (if any).
- removeAbandoned : (default false) Flag to remove abandoned connections if they exceed the removeAbandonedTimout. If set to true a connection is considered abandoned and eligible for removal if it has been idle longer than the removeAbandonedTimeout. Setting this to true can recover db connections from poorly written applications which fail to close a connection.
- removeAbandonedTimeout : (default 300) Timeout in seconds before an abandoned connection can be removed.
- logAbandoned : (default false) Flag to log stack traces for application code which abandoned a Statement or Connection.
- testWhileIdle : (default false) Flag used to test connections when idle.
Warning
The previous settings should be modified only by experienced users. Using wrong low values for removedAbandonedTimeout and minEvictableIdleTimeMillis may result in connection failures; if so try it is important to set-up logAbandoned to true and check your catalina.out log file.
More informations about the parameters can be found at the DBCP documentation.
GeoServer Set-up¶
Launch GeoServer and navigate to the section.
First, choose the PostGIS (JNDI) datastore and give it a name:
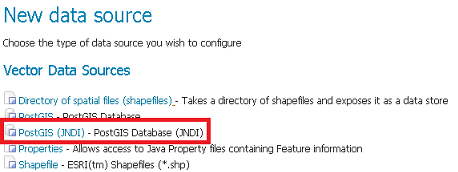
PostGIS JNDI Store Configuration
And then you can configure the connection pool:
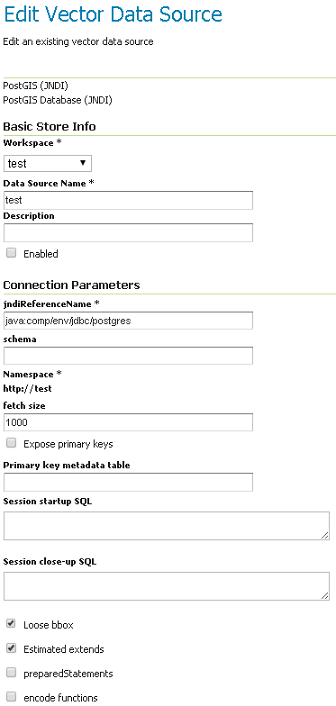
PostGIS JNDI Store Configuration
When you are doing this, make sure the schema is properly configured, or the DataStore will list all the tables it can find in the schema it is given access to.
Microsoft SQLServer JNDI Configuration¶
Before configuring a SQLServer connection pool you must follow these Guidelines.
Warning
You must remove the mssql-jdbc-9.2.0.jre8.jar file from the WEB-INF/lib folder and put it inside the $TOMCAT_HOME/lib folder.
Tomcat Set-up¶
In this case, we are going to configure a JNDI DataSource for a SQLServer database. You shall create/edit the context.xml file inside $TOMCAT_HOME/conf directory
with the following lines:
<Context>
<Resource
name="jdbc/sqlserver"
auth="Container"
type="javax.sql.DataSource"
url="jdbc:sqlserver://localhost:1433;databaseName=test;user=admin;password=admin;"
driverClassName="com.microsoft.sqlserver.jdbc.SQLServerDriver"
username="admin"
password="admin"
maxActive="20"
maxIdle="10"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
validationQuery="SELECT 1"/>
</Context>
Note
Note that database name, username and password must be defined directly in the URL.
GeoServer Set-up¶
Launch GeoServer and navigate to the section.
Then choose the Microsoft SQL Server (JNDI) datastore and give it a name:
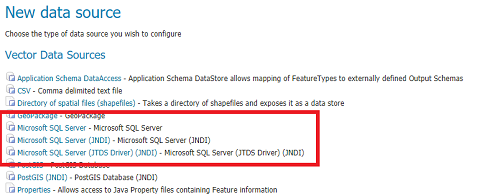
Microsoft SQLServer JNDI Store Configuration
After, you can configure the connection pool:
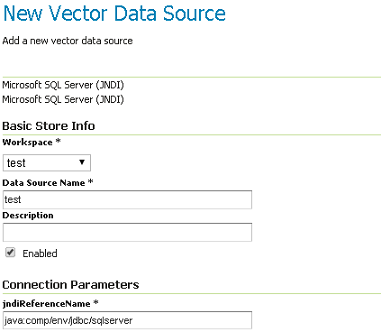
Microsoft SQLServer JNDI Store Configuration
Oracle JNDI Configuration¶
Before configuring an Oracle connection pool you should download the Oracle plugin from the GeoServer Download Page
and then put the the ojdbc8-19.10.0.0.jar file into the $TOMCAT_HOME/lib folder.
Warning
You must remove the ojdbc14.jar file from the WEB-INF/lib folder and put it inside the $TOMCAT_HOME/lib folder.
Tomcat Set-up¶
First you must create/edit the context.xml file inside $TOMCAT_HOME/conf directory with the following lines:
<Context>
<Resource
name="jdbc/oralocal"
auth="Container" type="javax.sql.DataSource"
url="jdbc:oracle:thin:@localhost:1521:xe"
driverClassName="oracle.jdbc.driver.OracleDriver"
username="dbuser"
password="dbpasswd"
maxActive="20"
maxIdle="3"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
poolPreparedStatements="true"
maxOpenPreparedStatements="100"
validationQuery="SELECT SYSDATE FROM DUAL" />
</Context>
GeoServer Set-up¶
Launch GeoServer and navigate to the section.
Then choose the Oracle NG (JNDI) datastore and give it a name:
Oracle JNDI Store Configuration
After, you can configure the connection pool:
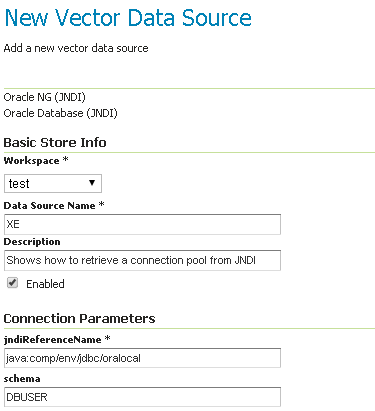
Oracle JNDI Store Configuration
Note
In Oracle the schema is usually the user name, upper cased.
Configuring Connection Pools for production usage¶
Connection waiting time and relation with other params¶
In general it is important to set the connection waiting time in a way that the connection pool does not become a place where to queue threads executing requests under big load. It is indeed possible that under big load threads executing requests for a vector layer will outnumber the available connections in the pool hence such threads will be blocked trying to acquire a new connection; if the number of connections is much smaller than the number of incoming requests and the max wait time is quite big (e.g. 60 seconds) we will find ourselves in the condition to have many threads waiting for a long time to acquire a connection after most of the resources they need will be allocated, especially the memory back buffer if these are WMS requests.
The max wait time in general shall be set accordingly to the expected maximum execution time for a requests, end-to-end. This include things like, accessing the file system, loading the data. As an instance if we take into account WMS requests we are allowed to specify a maximum response time, therefore if set this to N seconds the max wait time should be set to a value smaller than that since we don’t want to waste resources having threads blocked unnecessarily waiting for a connection. In this case it shall be preferable to fail fast to release resources that might be used unnecessarily otherwise.
Maximizing sharing of Connection Pools¶
How the data is organized between database, schemas and table impact the degree of flexibility we have when trying to best share connections, regardless of the fact that we were using JNDI pools or not. Summarising:
- Splitting tables in many schemas makes it hard for GeoServer to access table belonging to different schemas unless we switch to JNDI since the schema must be specified as part of the connection params when using internal pools.
- Using different users for different schemas prevent JNDI from working efficiently across schemas. It’s best to use when possible a single dedicated account across schemas.
- Generally speaking having a complex combination of users and schema can lead to inefficient split of available connections in multiple pools.
Long story short, whenever it’s possible strive to make use of a small number of users and if not using JNDI to a small number of schema, although JNDI is a must for organization willing to create a complex set up where different workspaces (i.e Virtual Services) serve the same content differently.
Query Validation¶
Regardless of how we configure the validation query it is extremely important that we always remember to validate connections before using them in GeoServer. Not doing this might lead to spurious errors due to stale connections sitting the pool. This can be achieved with the internal connection pool (via the validate connections box) as well as with the pools declared in JNDI (via the validation query mechanism). It is worth to remind that the latter will account for finer grain configurability.
Footnotes
| [1] | http://en.wikipedia.org/wiki/Java_Naming_and_Directory_Interface |
| [2] | http://commons.apache.org/proper/commons-dbcp/ |